This is a list of coding challenges that can be accomplished without too much effort after you have deeply learned how things work. It can be used to verify your learning.
Many seemingly complex topics have simple principles behind them, such as compilers, regular expressions. That’s why I used the “create it in 1 week” as a way to test my knowledge. If I still see a topic as complicated, I probably missed something and need to learn more.
Some developers will see part of the list as magic or very complex things. But they are still learnable things, and the more you learn the easier they get. Why not pick a topic and learn something new?
Big projects are broken down into smaller topics to give you ideas of where to start. The list does not include topics that are inherently complex.
Discuss on HackerNews.
Table of Contents:
- JSON Parser
- Calculator
- Compiler/Interpreter
- Regular Expression Engine
- Search Engine
- Database
- HTTP Server
- Terminal Games
- Web Spreadsheet
- GZIP/ZIP/PNG/GIF Decoder
- Unix Shell
- Ray Tracer
Other resources with a similar spirit:
- 500 Lines or Less, how experienced programmers
solve interesting problems.
[Amazon] [Web] - codecrafters.io, build-your-own-X style challenges.
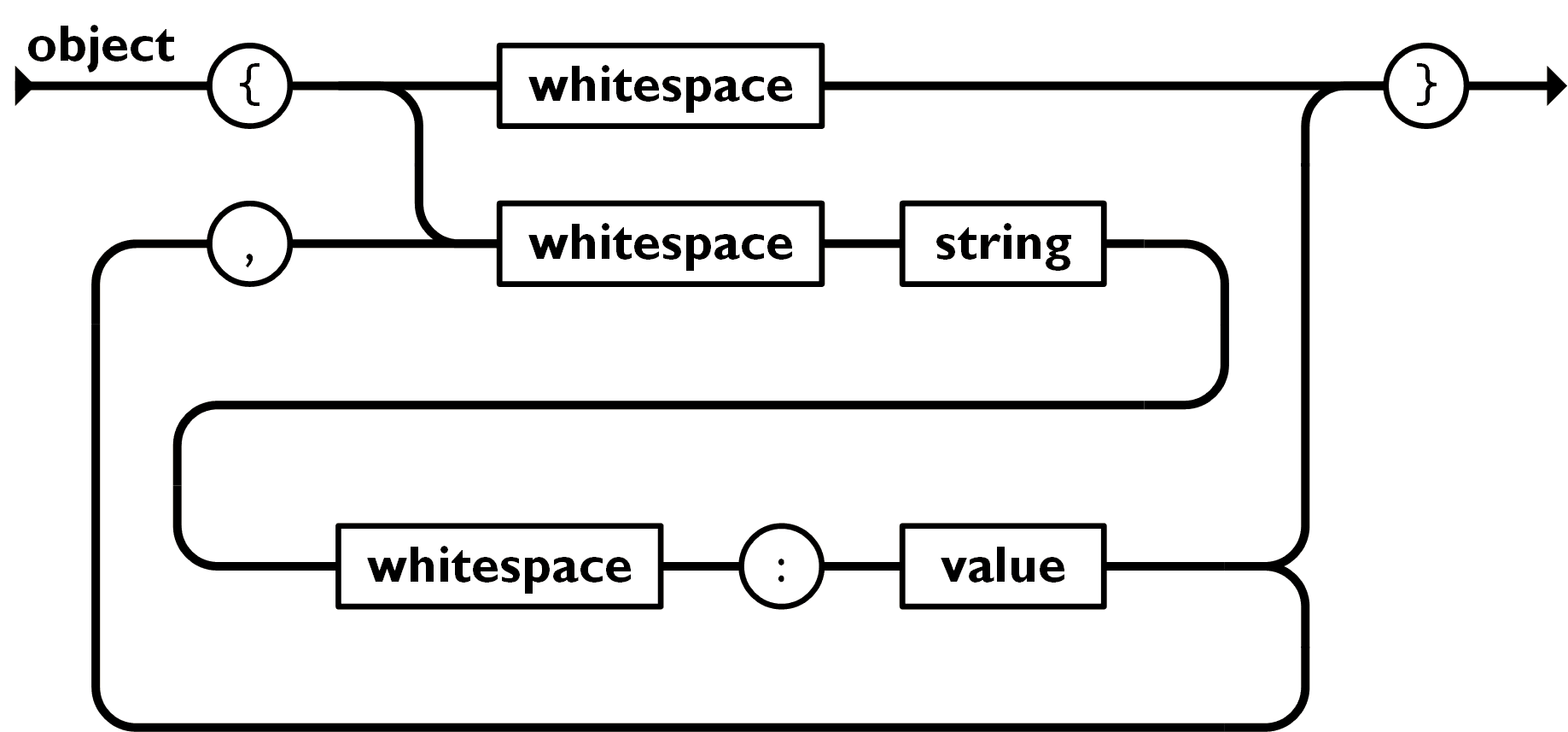
01. JSON Parser
Difficulty: ★☆☆☆☆
This list is not a pure coding challenge. There are important topics behind each project. For creating a JSON parser, the topic is recursion. There is a pattern that can be used to parse most computer languages, it is called recursive descent.
Many of the challenges on this list also require some parsing. So it is recommended that you start with this one.
Try to simplify the code when you are done. You probably learned about tokenizers or lexical analysis if you used a compiler book. These things are not necessary for something as simple as JSON, and they actually add more work.
Another reason this is worth doing: unlike most coding works, there is actually a precise specification to follow. Try to follow the JSON specification to the letter, because it trains you to think and code rigorously.
Things to learn:
- Recursive descent parsing.
- Follow a specification rigorously.
Recommended reading:
The Little Schemer by Friedman. [Amazon]
Some people consider this the best book on recursion, the book that makes recursion click.
02. Calculator
2.1 Reverse Polish Notation
Difficulty: ★☆☆☆☆
An RPN calculator is a simple application of the stack data structure. When it comes to data structure, many folks will think of LeetCode. How about coding something that resembles a useful thing? There are also hardware RPN calculators which you can try to emulate.

2.2 Infix Operators
Difficulty: ★★☆☆☆
The difficulty increases with operator precedence. There are special algorithms to handle this, such as the shunting yard algorithm, which converts infix operators to RPN using 2 stacks.
Another way to do this is the recursive descent method from the JSON parser challenge. You can learn how this works by reading some open source compiler code.
Recommended reading:
- Any introductory books on data structures.
03. Compiler/Interpreter
(It is recommended to do the JSON parser challenge and the calculator challenge before this.)
3.1 S-expression
Difficulty: ☆☆☆☆☆
If you know how to parse JSON and handle infix operators, you can probably parse most computer languages. Don’t do exercises for the sake of exercises, and given the “1 week” limit, it’s wise to skip what you already know and focus on the next thing.
Some compiler resources start with tools such as yacc
and flex, these topics are relatively less important and
can suck up a lot of time. Languages like C require a significant amount
of effort to parse, regardless of the methods. Starting with S-expressions will save
you time.
Things to learn:
- Use your time wisely.
3.2 Tree Walk Interpreter
Difficulty: ★★☆☆☆
The easy way to create a new programming language. You do not compile anything, you just simulate the program from a representation (AST). All you need is a mental model of how the program works, such as variables, scopes, and control flows.
The implementation can be very simple if the host language is high-level and the target language is dynamic; you can store variables in hash tables, borrow the GC from the host, or even abuse exceptions to simulate some control flows.
Things to learn:
- Representing a program within a program.
- Simulating a program within a program.
Recommended reading:
Learn C · Build Your Own Lisp by Daniel Holden. [Amazon] [Web]
A beginner-friendly book that teaches you many things at once, including parsers, interpreters, the C programming language, and more. C is unavoidable if you want to learn low-level stuff.
3.3 Transpile to C
Difficulty: ★★☆☆☆
This allows you to get rid of the host language. Try to do more than a syntax converter by adding high-level features that don’t exist in C, such as a GC, or an object system. A simple stop-the-world-then-mark-and-sweep GC isn’t much magic.
Things to learn:
- How high-level language features work.
3.4 Bytecode + VM
Difficulty: ★★★★☆
One step closer to real-world compilers. There are many VM designs to choose from, some of them simple enough to do in 1 week, if you keep the other parts small.
Things to learn:
- How programs work at a lower level.
- How computers work in general. If you used a register-based VM.
Recommended reading:
Crafting Interpreters by Robert Nystrom. [Amazon] [Web]
Has almost everything you need to know about creating your own programming language. Covers both interpreters and bytecode compilers.
3.5 Compile to Assembly or Machine Code
Difficulty: ★★★★☆
The prerequisite is learning assembly. But you only need to know a small subset of assembly, enough to translate a C-like low-level language.
You can skip the register allocation by loading variables into predefined temporary registers before doing arithmetic, kinda like unoptimized GCC output. Or you can use a stack-based design that only operates only on the stack top.
Things to learn:
- Assembly and how to program with it.
- How programs work on a real computer.
Recommended reading:
From Nand to Tetris by Noam Nisan. [Amazon] [Web]
Gives you the full picture of how computers work — from logic gates to software.
I’ll share the results of my own learning: From Source Code to Machine Code.
04. Regular Expression Engine
Recommended reading:
Implementing Regular Expressions by Russ Cox. [Web]
A series of easy-to-read tutorials on implementing regular expression engines with different methods. This will definitely fit within 1 week after you understand it.
4.1 Tree Representation
Difficulty: ★★☆☆☆
The first step is to parse the regex into a syntax tree. There are many challenges in this list that can teach you about parsing, especially the infix calculator challenge.
The resulting tree should have 4 types of nodes:
- Alternation.
- Concatenation.
- Repetition.
- Character.
4.2 Backtracking
Difficulty: ★★★☆☆
This method requires the least amout of knowledge. The idea is simple: each node tries all possible matches. This method is very flexible and is used in feature-rich regex engines such as Perl. However, it is subject to exponential worst cases.
Things to learn:
- Backtracking. A basic algorithm concept.
4.3 Finite Automata
Difficulty: ★★★★☆
The next idea is to treat regex as a graph, you start from somewhere in the graph, then travel to the next locations with each character from the input. Due to alternations and repetitions, there are multiple possible locations after each step. The traversal works from one set of locations to another set of locations until the end of the regex is reached. This is called a nondeterministic finite automaton (NFA).

If we precompute all possible transformations from location set to location set, we can match the regex in O(n). This is called a deterministic finite automaton (DFA).
Things to learn:
- An application of graph data structure.
- NFA & DFA.
4.4 Extra Projects
- Create visualizations using graphviz for the NFA and DFA things.
- Build your own
grep.
Things to learn:
- Just for fun.
05. Search Engine
A bare minimal search engine consists of just 3 components: inverted indexing, boolean operators, and ranking functions. None of these are hard to implement for a toy search engine. You can also ignore updatable indexes and focus on creating static indexes instead.
5.1 Inverted Index
Difficulty: ★☆☆☆☆
grep’ing through files is not an efficient way to
retrieve information. Classic full-text search is based on the idea of
inverted indexes, which is a mapping from the term to
a list of document IDs containing the term. The index can rule
out irrelevant documents that don’t even contain any of the query
terms.
Recommended reading:
The Anatomy of a Large-Scale Hypertextual Web Search Engine by Sergey Brin and Lawrence Page. [Web]
The early version of Google gives you a lot of insight into information retrieval at scale.
Managing Gigabytes by Ian H. Witten. [Amazon]
Covers the technical details of actually building your own search engine. Don’t be fooled by the “gigabytes” in the title, it is still one of the best books on information retrieval after 2 decades.
5.2 Tokenization
To make use of inverted indexes, the document must be broken down into terms, which are often just English words. A process called stemming is used to normalize different word forms into a canonical form.
The “term” is not limited to text words; the properties of an item, such as the dimension of the item, the price of the good, can also be indexed.
5.3 Boolean Operations
Difficulty: ★☆☆☆☆
More advanced use cases require the use of boolean operators, such as “cat AND food”, “cat OR dog”, “cat AND (NOT Linux)”. This is done by combining or intersecting multiple subqueries. Parsing the boolean expression is similar to many other challenges involving parsing.
5.4 Ranking
Difficulty: ★★☆☆☆
The general procedure of a search engine is:
- Find relevant documents via inverted indexes.
- Rank and return the top K results.
The larger the dataset the more important ranking is. The ranking method can be unrelated to the query such as rank by time, or query dependent such as TF-IDF.
Recommended reading:
Relevant Search by Doug Turnbull. [Amazon]
A comprehensive book that gives you practical knowledge instead of abstract concepts. How do you combine multiple scores? Should you add or multiply? You wouldn’t even think about these problems until you actually had a use case. That’s why the knowledge in this book is so valuable.
5.5 Vector Search
TBA
06. Database
Even a toy database probably wouldn’t fit in 1 week. But there are many smaller aspects of databases that you can explore. You can choose one of the topics at a time.
Recommended reading:
Database Internals by Alex Petrov. [Amazon] [Web]
Rather than talking about topics from a high level, this book goes down to the practical side and examines databases in detail. Covers many different options for storage engines.
6.1 In-Memory Hashtable or AVL Tree
Difficulty: ★★☆☆☆
Data structures are central to many topics, especially to databases. Why not start with implementing basic data structures? You can view this as a prerequisite — build an in-memory KV.

Things to learn:
- Review your knowledge of common data structures.
Recommended reading:
A Common-Sense Guide to Data Structures and Algorithms by Jay Wengrow. [Amazon]
Explains data structures and algorithms in a simplified way. It relies heavily on diagrams instead of math and jargon. Give this book a try if you find data structures too hard or useless and it will change your mind.
6.2 In-Memory B+Tree
Difficulty: ★★★★☆
B-trees are still simple in concept. You are now one step closer to building a database. The implementation may be harder than you thought, and may take you more than 1 week, through.
A tutorial on B+tree by myself: B-Tree: The Practice.
6.3 Append-Only Log + In-Memory Indexing
Difficulty: ★★☆☆☆
One of the most important aspects of databases: durability. Calling this a database is a stretch, as this is more like an in-memory KV with extra persistence. But this is simple enough for your first try.
Things to learn:
- Why is log used in databases?
- Making data durable via
fsync.
6.4 LSM-Tree
Difficulty: ★★★☆☆
Upgrade the log to the Log-structured merge-tree — an alternative to B+tree. The data structure is much easier than B+tree. And you don’t have to worry about recycling deleted pages.
To my knowledge, LSM-tree is probably the easiest way to achieve durable and disk-indexed databases of reasonable completeness.
Things to learn:
- How does LSM-tree work?
- On-disk static data structures that can be efficiently queried.
6.5 CoW B+Tree
Difficulty: ★★★★★
Copy-on-write B+tree. Being copy-on-write simplifies many things. It is harder to corrupt the database because the DB creates a new version of the tree instead of overwritting data in place. You can also easily achieve multi-reader-single-writer concurrency. These upsides apply to the LSM-tree as well.
Things to learn:
- Managing disk pages.
- The power of immutable data structures.
6.6 Relational DB on KV
Difficulty: ★★★☆☆
If you have a KV, you can try to add tables, secondary indexes, a query language, etc.
07. HTTP Server
Difficulty: ★★★☆☆
Many application performance problems are related to networking. And you can learn a lot about computer networking by creating networked applications.
HTTP/1.1 is a good target is because it’s human-readable, so you can grok it by looking at examples. It’s also a useful skill, because if you can create an HTTP server, you can create other networked apps as well.
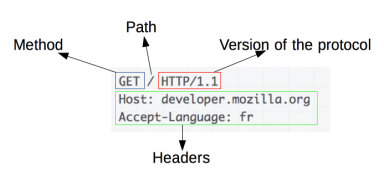
Things to learn:
- Socket programming.
- Network protocols.
- Event loops, non-blocking IO, and multi-threading; if you avoid high-level libraries.
Recommended reading:
Beej’s Guide to Network Programming. [Amazon] [Web]
A comprehensive guide and reference to network programming in C. Even if you don’t use C, the guide is still the best for learning the basic concepts. And jumping into a high-level networking library can be confusing without learning the basics first.
High Performance Browser Networking by Ilya Grigorik. [Amazon] [Web]
While the title says “browser”, this is a general and practical networking book. The knowledge is applicable to fixing performance problems in any networked application.
08. Terminal Games
Difficulty: ★☆☆☆☆
Many people have wanted to create games, but stopped because they didn’t know how to do graphics on the computer. Did you know that you can create games like Tetris or Minesweeper in a terminal? It turns out that a terminal can do a lot of things:
- Colored text and symbols.
- Move the cursor.
- Read mouse and keyboard input.
- Bitmap graphics via sixel.
These functionalities are achieved by sending special commands, known as the escape sequences, to the termimal. That’s all you need to create games.
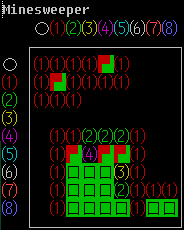
Why is creating games on this list? Because games deal with multiple sources of input, and the game passively reacts to events rather than actively deciding what to do next. Taking Tetris as an example, the game reacts to both keyboard events and timer events, which inevitably ends up in something resembling an event loop — an important pattern also used in GUI apps and network programming.
Things to learn:
- Event-based programming.
- Separating logic from input.
Recommended reading:
Game Programming Patterns by Robert Nystrom. [Amazon] [Web]
The game code in this book is practical code, unlike the other “pattern” books you may have heard of. The book also covers performance tips that are useful outside of games.
09. Web Spreadsheet
Difficulty: ★★☆☆☆
Even if you are not a web developer, creating web-based apps is still a useful skill because it allows you to create UIs and visualizations.
A web spreadsheet will familiarize you with common web programming skills such as DOM tree manipulation, stylesheets, layouts, and debugging in the browser.
Formulas are a core feature of any spreadsheet software, and supporting formulas requires tracking dependencies between cells. This is another use of graph data structures.
Things to learn:
- Web programming basics.
- Dependency graph.
- Parser (for formulas).
Recommended reading:
Fundamentals of HTML, SVG, CSS and JavaScript for Data Visualisation by Peter Cook. [Amazon]
You may also be interested in visualization as it is the obvious use case of the web. This small book can get you started with zero prior experience.
10. GZIP/ZIP/PNG/GIF Decoder
Difficulty: ★★★★☆
You may be wondering why these file formats? What do they have in common? All of them are based on the same data compression algorithm: deflate.
Compression is achieved through 2 steps:
- Replacing duplicate strings with references – the LZ algorithm.
- Encoding symbols by varying bit lengths based on their frequency — the Huffman coding.
At first glance, these algorithms seem very complex. But fortunately, decoding is much easier than encoding, and that’s where we’ll start.
Decoding the LZ algorithm is mostly copying data according to instructions. Decoding Huffman coding is harder, but still easier than encoding. Here is a fully dissected GZIP file.
Things to learn:
- LZ algorithm and Huffman coding.
- Read specifications and turn them into code.
Recommended reading:
Understanding Compression by Colt McAnlis and Aleks Haecky. [Amazon]
A delightful read for a niche topic.
11. Unix Shell
Difficulty: ★★★☆☆
Even if you don’t use Linux, you have probably been exposed to Unix shells. Most servers run Linux, and even Microsoft is embracing Linux via WSL. Command line and shell skills are becoming mandatory for software developers.
When most people think of shells, they think of Bash, with its chaotic syntax and footgun rules for quotes and spaces. But beneath the surface is the Unix way of computing: processes, pipes, everything is a byte stream, etc. These are much more interesting topics to learn than the shell itself.
Things to learn:
- The fork & join model of computing.
- Pipes; the producer and consumer problem.
- The Unix API.
Recommended reading:
The Linux Programming Interface by Michael Kerrisk. [Amazon] [Web]
Written by the people who maintain the Linux man-pages, clearly explained, and comes with sample programs to teach you how to actually use the API.
Operating Systems: Three Easy Pieces by Remzi H. Arpaci-Dusseau. [Amazon] [Web]
Before jumping into system programming, you should equip yourself with the knowledge of general operating system concepts. This concise book is perfect for filling the gap for people without a CS background.
12. Ray Tracer
Difficulty: ★★★☆☆
You are probably reading this through a colored display. Have you ever thought about creating 3D graphics on your computer? It turns out that there is an easy way to get started with computer graphics — ray tracing.

The idea of ray tracing is simple: cast a ray from your eye, if it hits an object, it bounces until it hits a light source, calculate the color and intensity of the ray. For each pixel on the screen, cast multiple rays in that direction and use the average as the value of the pixel.
Sounds simple enough, but how do you code it? To build a ray tracer, you first need to understand 3D geometry and the related math, which can be daunting for some people.
Things to learn:
- Introductory computer graphics.
- 3D geometry.
Ray Tracing in One Weekend by Peter Shirley. [Amazon] [Web]
A concise book that will lead you to pretty pictures of spheres. It doesn’t require too much prior knowledge. There are also follow-up books that go further.
3D Math Primer for Graphics and Game Development by Fletcher Dunn. [Amazon] [Web]
3D graphics is more about math than programming. This book fills many gaps that programmers may lack.



